Modellauswahl
Zuletzt aktualisiert Vor 11 Monaten
Diese Referenz erläutert (1) die verfügbaren Modelle, (2) die Funktionsweise der automatischen Modellauswahl und (3) die Funktionsweise der manuellen Modellauswahl.
Verfügbare Modelle
Dateiunterstützung: Alle Modelle unterstützen alle Dateiformate: PDF, DOCX, TXT, PPTX (Dateien werden während des zusätzlichen Analyseschritts von MAIA in Text umgewandelt).
Auto Model Selection (Standard)
Wie es funktioniert:
Analyse pro Anfrage: Bei jeder einzelnen Anfrage analysiert MAIA den Fragetyp, bevor es antwortet.
Modellauswahl: Ein Entscheidungssystem wählt das optimale Modell auf der Grundlage von Benchmark-Daten für verschiedene Aufgabentypen aus.
Dynamisches Wechseln: Modelle können innerhalb desselben Chats je nach Frageinhalt zwischen Abfragen wechseln.
Entscheidungsgrundlage: Große Vergleichstabelle, die die Modellleistung für verschiedene Aufgabentypen zeigt
Transparenz: Wenn „Auto Model“ aktiviert ist, wird oben in jeder Abfrage angezeigt, welches Modell verwendet wurde (nachdem die vollständige Antwort erstellt wurde).

Manuelle Modellauswahl
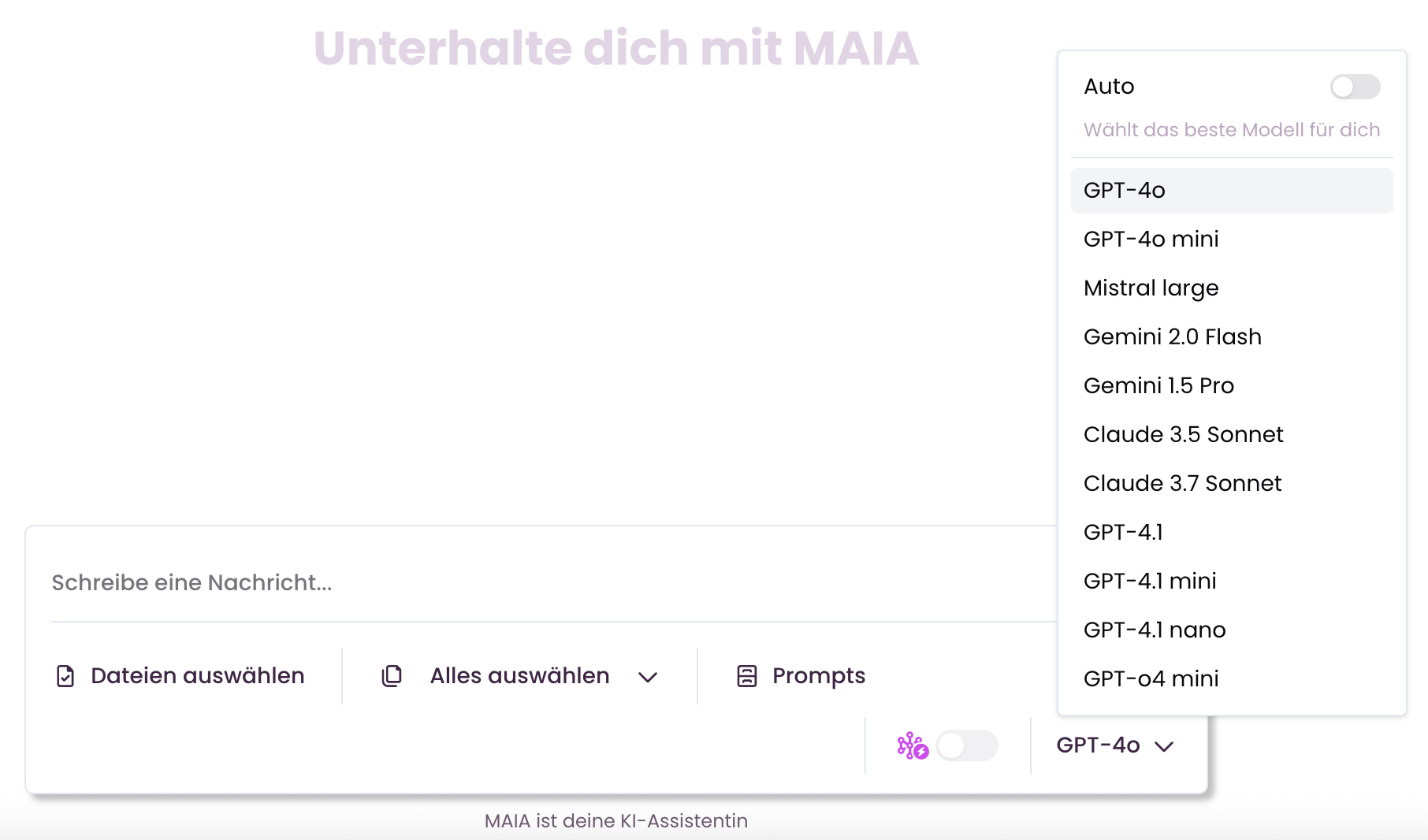
So aktivieren Sie die Funktion:
Automatische Modellauswahl in der Chat-Oberfläche deaktivieren
Wählen Sie Ihr bevorzugtes Modell aus der Dropdown-Liste aus.
Persistenz: Ihre Auswahl bleibt für alle zukünftigen Abfragen und neuen Chats bestehen.
Wie es funktioniert:
Einzelauswahl: Modell einmal auswählen, gilt für alle nachfolgenden Abfragen
Konsistente Erfahrung: Es wird dasselbe Modell verwendet, bis Sie es manuell ändern.
Cross-Chat-Persistenz: Das ausgewählte Modell bleibt in neuen Unterhaltungen aktiv.
Reasoning Modelle
Gemini 2.5 Pro und Claude 4 Sonnet unterstützen sogenanntes Reasoning. Dabei „denkt“ das Modell zuerst intern über eine Anfrage nach, bevor es die eigentliche Antwort formuliert. Es nutzt dafür zusätzliche Zwischenschritte („Thinking Tokens“), die helfen, komplexe Aufgaben besser zu bearbeiten. Da das Modell intern mehr Schritte durchläuft, können Reasoning-Antworten etwas länger dauern als normale Antworten. Das ist normal und bedeutet, dass das Modell aktiv „nachdenkt“.
Reasoning kann je nach Modell automatisch im Auto-Modus aktiviert sein oder über das Modell manuell ausgewählt werden. Für jede Nutzerin und jeden Nutzer stehen aktuell 50 Reasoning-Anfragen pro Modell in einem Rolling-30-Tage-Fenster zur Verfügung.
Nach Erreichen des Limits wird das Modell aus dem Auto-Modus ausgeschlossen. Die Anzahl der Thinking Tokens, die ein Modell für seine „Gedanken“ einsetzen darf, hängt vom Anbieter ab:
Claude 4 Sonnet arbeitet mit einem Budget von bis zu 16.384 Thinking Tokens
Gemini 2.5 Pro mit bis zu 32.768 Thinking Tokens
Diese Tokens sind nicht sichtbar. Sie laufen im Hintergrund und dienen ausschließlich dazu, die Qualität der Antworten zu verbessern.